深入了解 OpenAI 的内部数据智能体
https://openai.com/zh-Hans-CN/index/inside-our-in-house-data-agent/?utm_source=engineering.fyi
作者:Bonnie Xu、Aravind Suresh 和 Emma Tang,刘剑波编译
数据为系统如何学习、产品如何演进以及企业如何做出选择提供动力。但要快速、准确地获取答案,并结合相关上下文,往往比想象中更为困难。随着 OpenAI 业务范围的扩展,为了简化这项工作,我们建立了专属定制内部 AI 数据智能体,通过 OpenAI 的平台进行探索和推理。
我们的智能体是一款定制内部专用工具(非外部产品),围绕 OpenAI 的数据、权限和工作流而构建。我们将展示 OpenAI 如何构建和使用这一工具,以帮助大家了解 AI 如何以切实可行的方式,支持团队完成日常工作。我们用于构建和运行这一智能体的 OpenAI 工具(Codex、我们的 GPT‑5 旗舰模型、Evals API(在新窗口中打开) 和 Embeddings API(在新窗口中打开))与我们提供的面向全球各地开发人员的工具相同。
我们的数据智能体可支持员工在几分钟(而非几天)内从问题中提取洞察数据。这降低了所有职能部门(而不仅仅是我们的数据团队)提取数据和进行细致分析的门槛。如今,OpenAI 的工程、数据科学、市场进入、财务和研究团队都依赖智能体来解答高价值数据问题。例如,它可以通过直观的自然语言格式,回答如何评估发布流程和理解业务运行状况等问题。该智能体结合了 Codex 驱动的表格级知识,以及产品和组织的上下文信息。其持续学习记忆系统意味着它能够在每一轮的问询中获得优化。

在这篇文章中,我们将深入分析为什么我们需要定制 AI 数据智能体,代码增强型数据上下文和自学习功能为何如此重要,以及我们在此过程中汲取的经验教训。
为什么我们需要定制工具
OpenAI 的数据平台为工程、产品和研究部门的 3,500 多名内部用户提供服务,涵盖 70,000 个数据集中超过 600 PB 的数据。在此规模下,寻找合适的表格可能是分析过程中最耗时的环节之一。
正如一位内部用户所解释的:
“我们有很多非常相似的表格,我曾耗费大量时间去厘清它们的不同之处,以及具体应选择哪一个表格。有的表格包括已注销用户,有的则不包括这些用户。有的表格存在重叠字段,很难分辨具体内容。”
即使选择了正确的表格,生成正确的结果也并非易事。分析师必须对表格数据和表格关系进行推理,以确保正确应用转换和筛选功能。常见的故障模式 — 多对多连接、筛选条件下推错误和未处理的空值,都可能会在不知不觉中输出无效结果。鉴于 OpenAI 庞大的组织架构,分析师不应将时间浪费在调试 SQL 语义或查询性能上:他们的重点应放在定义指标、验证假设和制定数据驱动的决策。

工作原理
让我们逐步了解 OpenAI 的智能体及其如何整理上下文并不断自我完善。
我们的智能体由 GPT‑5.2 驱动,旨在通过 OpenAI 的数据平台进行推理。无论员工在何处办公,都可以使用这一工具:它能够充当 Slack 智能体、通过 Web 界面、嵌入集成开发环境 (IDE)、经由 MCP 连接的 Codex CLI(在新窗口中打开) 以及直接通过 MCP 连接器在 OpenAI 的内部 ChatGPT 应用中调用(在新窗口中打开)。
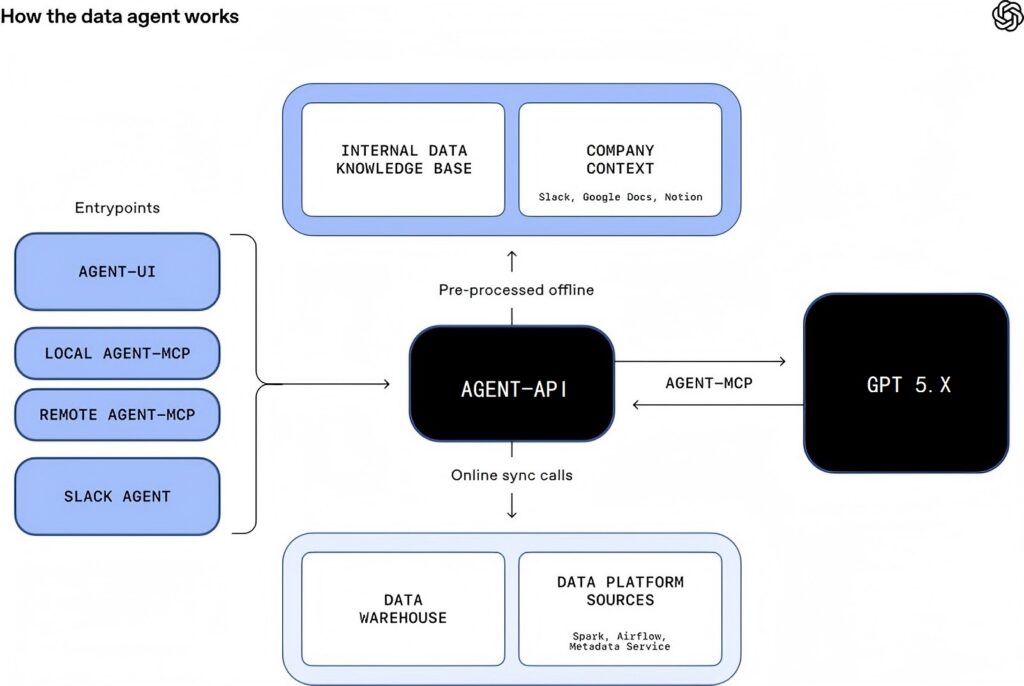
用户可以提出复杂的开放式问题,这通常需要多轮人工探索。以使用测试数据集的提示为例:“For NYC taxi trips, which pickup-to-dropoff ZIP pairs are the most unreliable, with the largest gap between typical and worst-case travel times, and when does that variability occur?” (“在纽约的出租车旅行中,哪些上下车路线推理是最不可靠的,哪些最差路线与最佳路线相差时间最大,以及为什么会发生这些时差?”)
从理解问题到探索数据、运行查询和汇总结果,智能体可负责承担端到端的全程分析。分析数据查询图表
智能体的文字分析
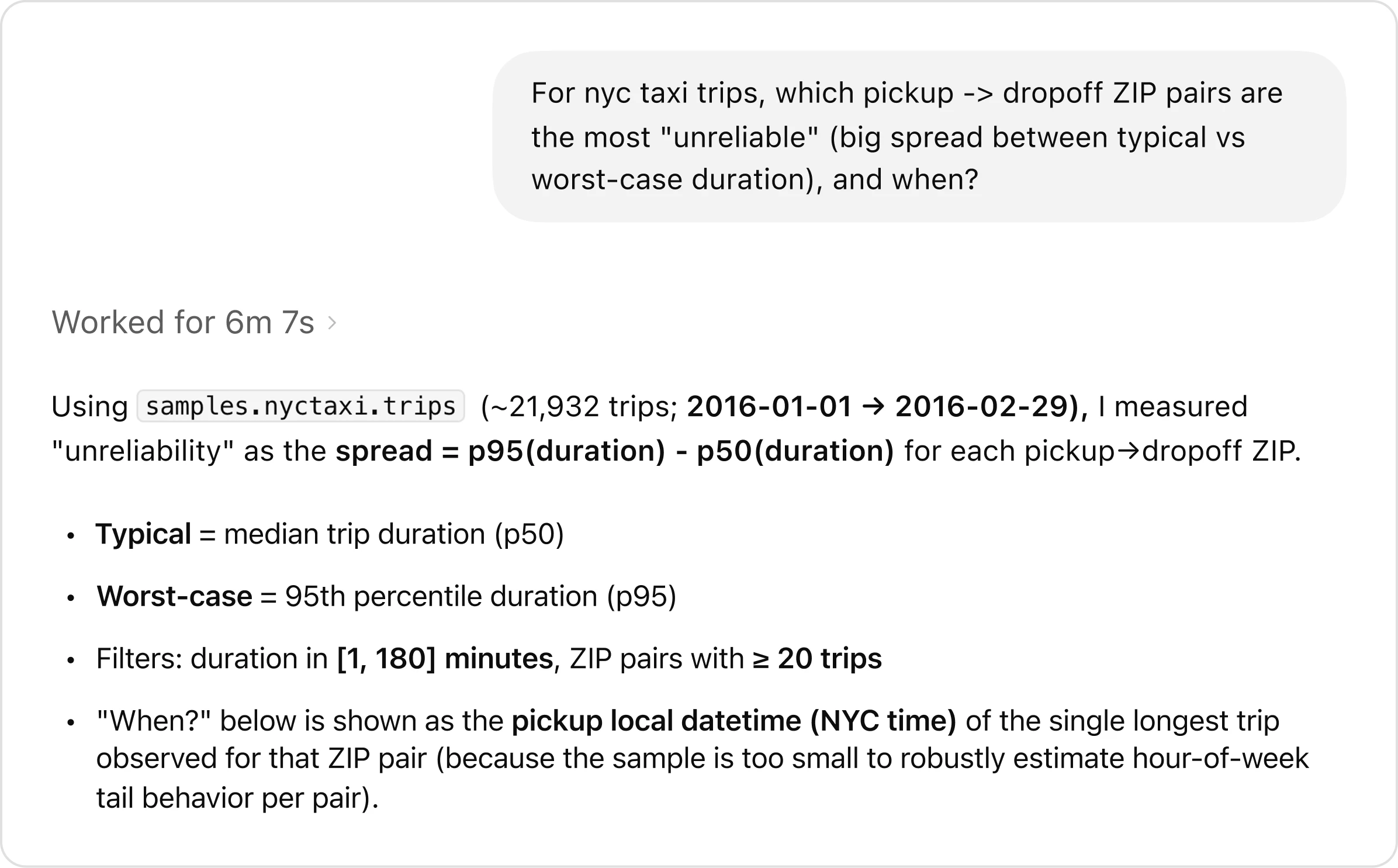
智能体的数据分析
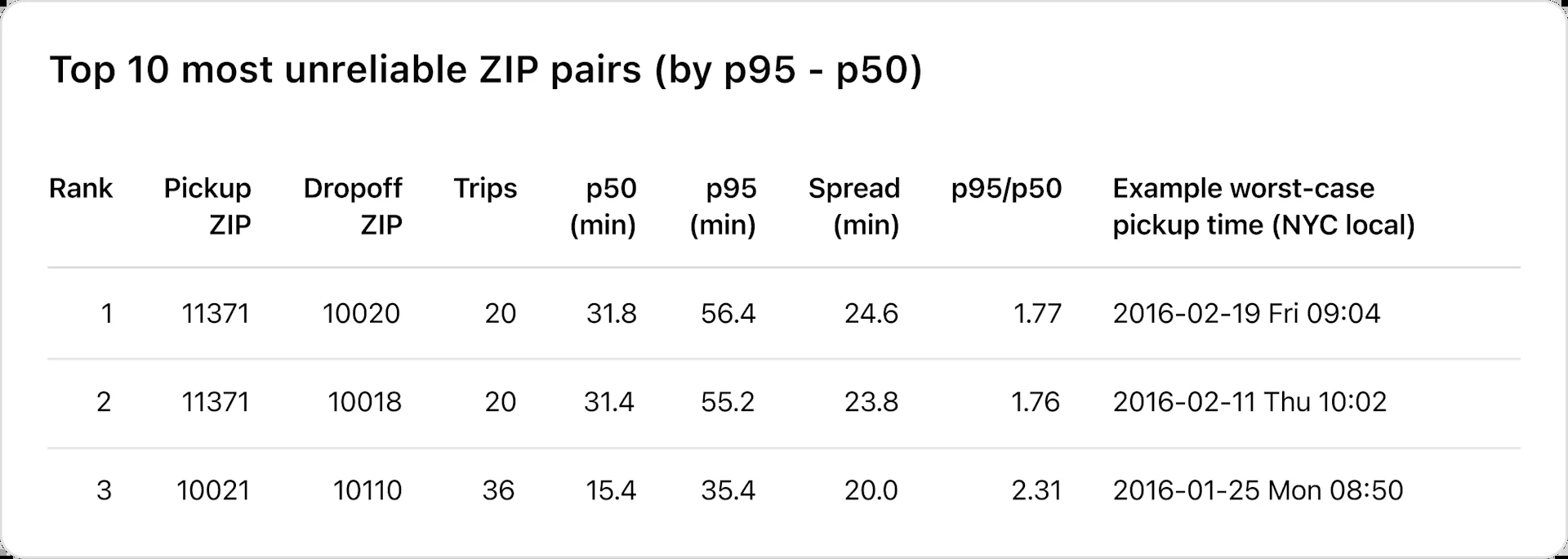
智能体的查询语句
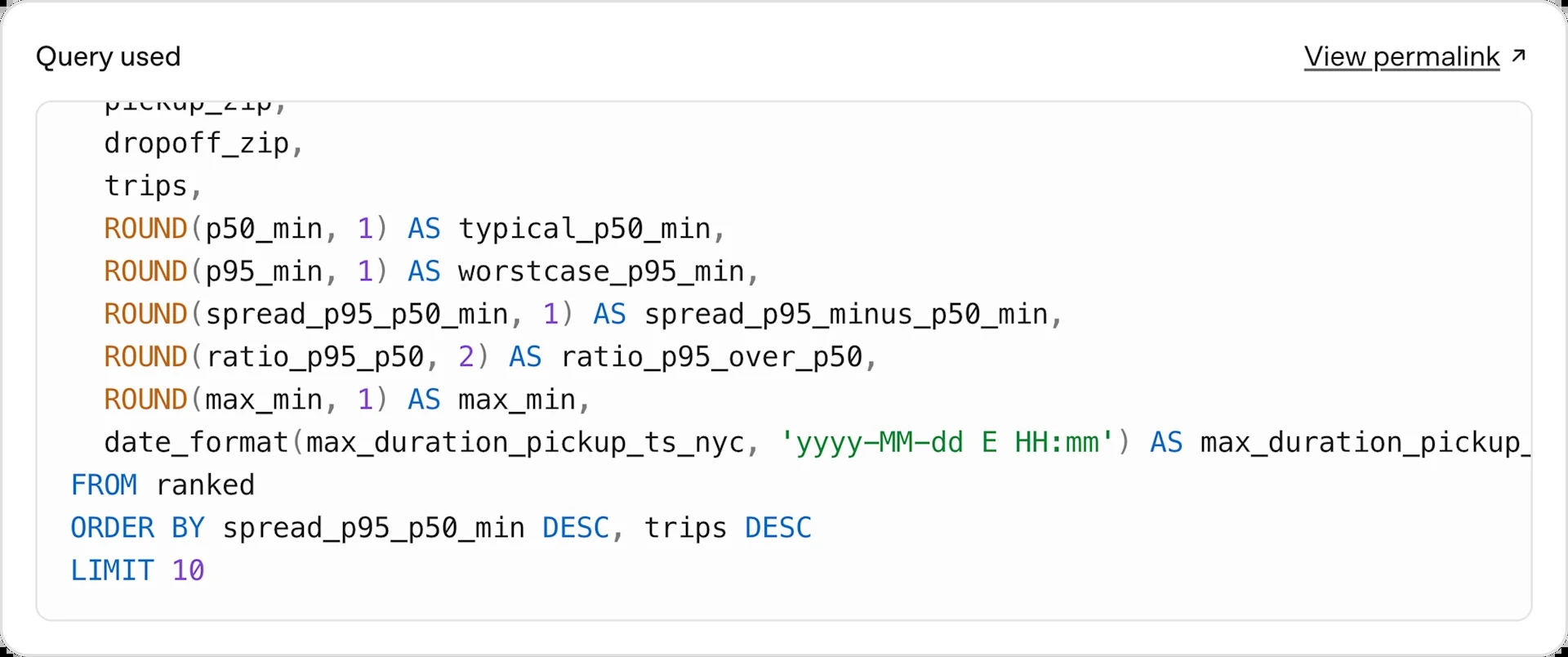
智能体的生成图表
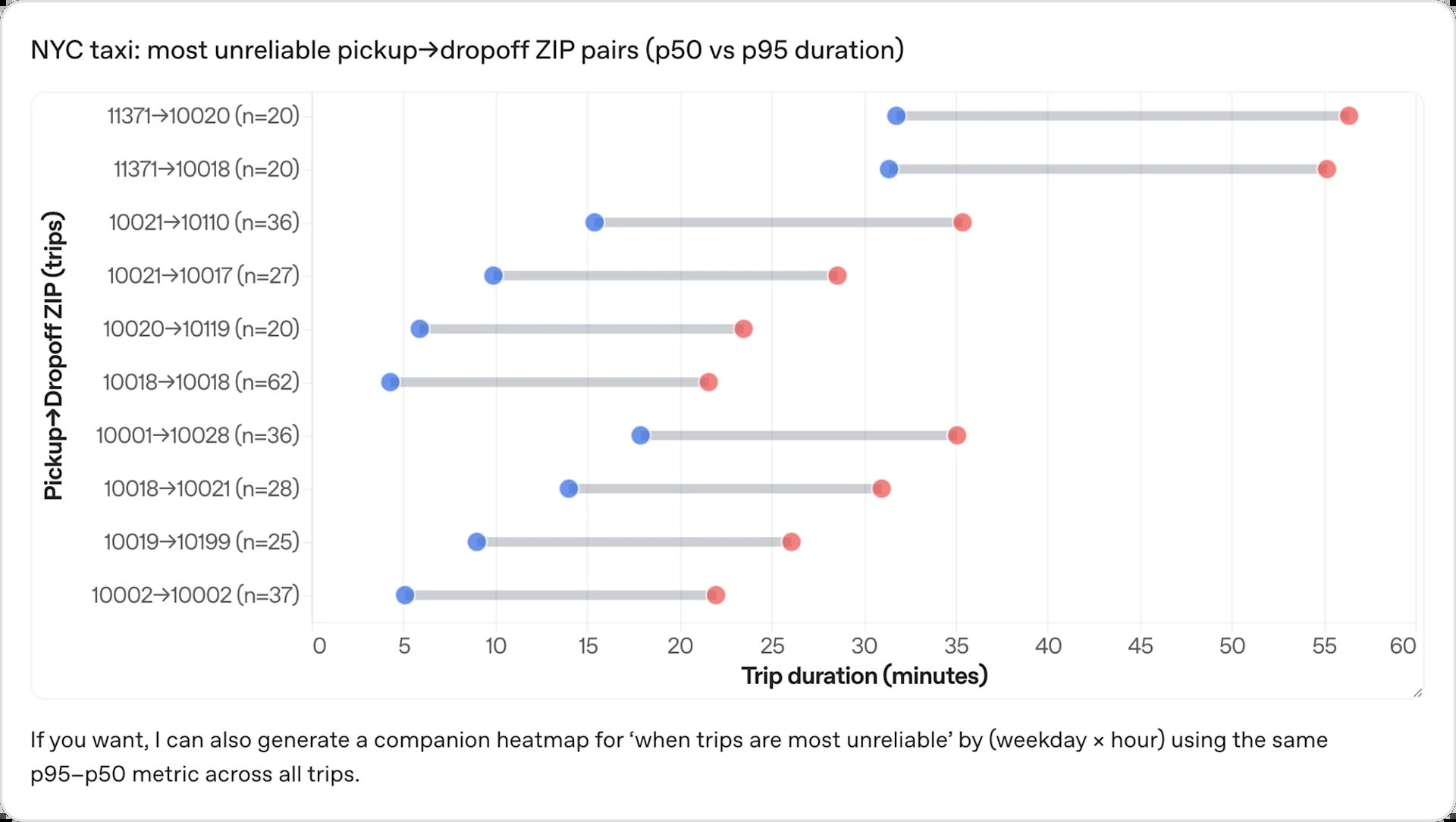
以上是智能体对问题的答复。
智能体的一项核心优势在于其解决问题的推理能力。智能体并非遵循固定的脚本,而是会自行评估流程进展。如果某个中间结果出现异常(例如,由于错误的连接或筛选操作导致行数为零),智能体就会调查出现非问题的具体环节,调整其方法,并再次尝试。在此过程中,它会保留完整的上下文,并在各步骤之间传递学习成果。这一闭环式、自学习过程可将迭代推理、训练的任务数据集从用户提炼至智能体自身,从而更快输出结果,并持续提供质量远高于手动分析数据的工作流程。
该智能体现已涵盖完整的分析工作流:发现数据、运行 SQL、发布笔记及报告。它能够理解企业内部知识,通过网络搜索获取外部信息,并不断积累记忆以实现持续优化。
上下文决定一切
高质量的答案取决于丰富、准确的上下文。在缺乏上下文的情况下,即使是强大的模型也可能会输出错误结果,例如严重误估用户数量或曲解内部术语。
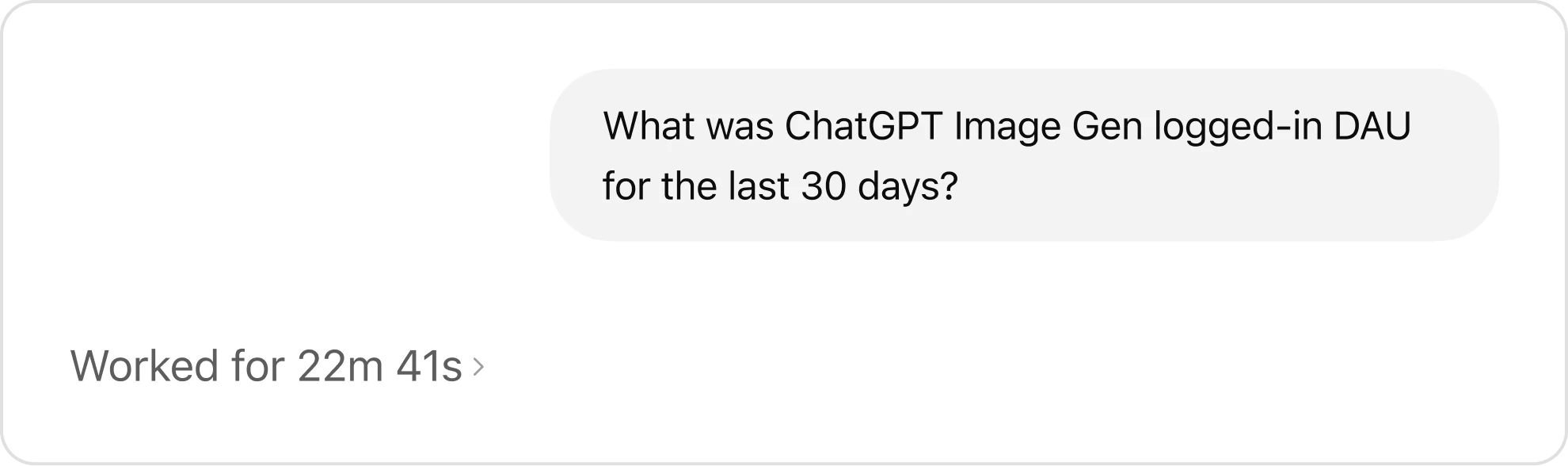
没有记忆能力的智能体,无法有效进行查询。
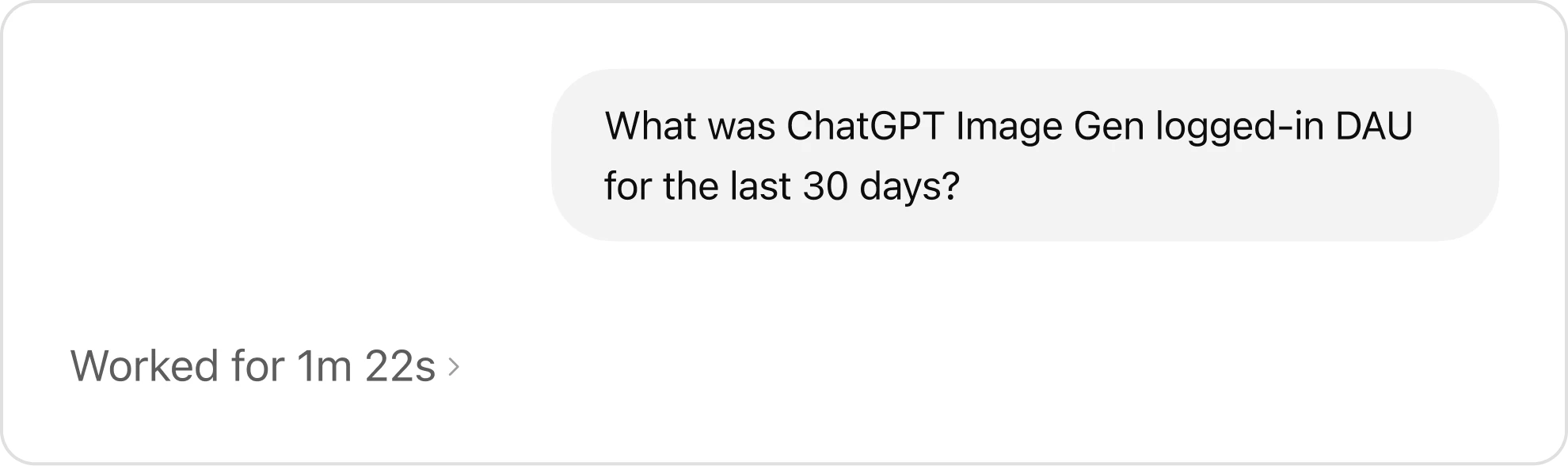
智能体的记忆可通过定位正确的表格,加快查询速度。
为了避免这些故障模式,我们围绕多层上下文构建智能体,并以 OpenAI 的数据和机构知识为基础。
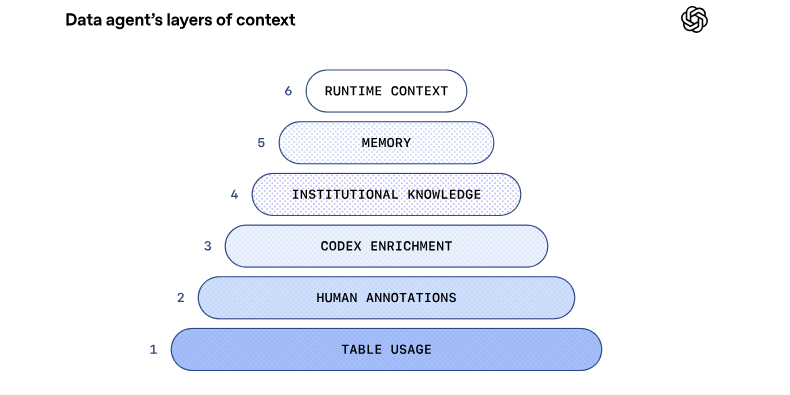
第 1 层:表格使用情况
- 元数据基础:智能体依赖模式元数据(列名和数据类型)来指导 SQL 编写,并使用表格沿袭(例如,上游和下游表格关系)来理解不同表格之间的上下文。
- 查询推理:采集历史查询有助于智能体理解如何编写查询,以及哪些表格通常相互关联。
第 2 层:人工注释
- 精选描述:由领域专家精心整理的表格和列相关描述,用于记录意图、语义、业务含义,以及无法从模式或过往查询中轻易推断的已知注意事项。
仅靠元数据是不够的。要真正区分表格,你需要了解其创建方式及来源。
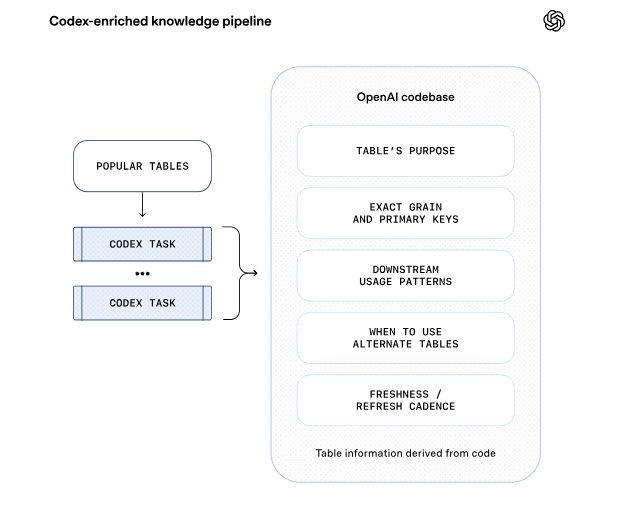
第 3 层:Codex 增强
- 通过推导表格的代码级定义,智能体能够更深入地理解数据的实际内容。
- 关于表格中存储的内容以及如何根据分析事件中得出的细微差别提供额外的信息。例如,它可以提供关于值的唯一性、表格数据更新频率、数据范围(例如,如果表格排除某些字段,即标识其具备相应的粒度级别)等上下文。
- 通过展示如何在 Spark、Python 和其他数据系统中使用 SQL 以外的表格,提供更丰富的使用情况上下文。
- 这意味着,智能体可以区分内容相似但存在关键差异的表格。例如,它可以判断某个表格是否仅包含第一方 ChatGPT 流量。该上下文还会自动刷新,因此无需手动维护即可保持更新。
第 4 层:机构知识
- 智能体可以访问 Slack、Google Docs 和 Notion,这些平台可记录关键的企业上下文信息,例如产品发布、可靠性事件、内部代号和工具,以及关键指标的规范定义和计算逻辑。
- 这些文档会被采集、嵌入,并与元数据和权限一起存储。检索服务可在运行时处理访问控制和缓存,支持智能体高效且安全地获取这些信息。
第 5 层:记忆
- 当智能体收到更正信息或发现某些数据问题存在细微差别时,它能够保存这些学习结果以供后续使用,从而在与用户交互的过程中持续改进。
- 因此,未来的答案将以更准确的基线为切入点,而非反复处理相同的问题。
- 记忆的目标是保留并复用那些不易察觉的更正信息、过滤条件和约束限制,这些内容对于维持数据的正确性至关重要,但仅凭其他层级难以有效推断。
- 例如,在某个案例中,智能体不知道如何筛选特定的分析实验(它需要依赖与实验门中定义的特定字符串进行匹配)。在此过程中,记忆至关重要,因为这一能力可确保智能体正确筛选相关信息,而非盲目尝试进行字符串匹配。
- 当你向智能体提出更正意见,或者当其从对话中查找学习内容时,它会提示你保存记忆,以备后续使用。
- 用户也可以手动创建和编辑记忆。
- 记忆的范围涵盖全局和个人层面,而智能体所配备的工具将简化编辑流程。

第 6 层:运行时上下文
- 如果表格缺乏先前的上下文或现有信息过时,智能体可以向数据仓库发起实时查询,以直接检查和查询该表格。这使其能够验证模式、实时理解数据,并做出相应的回复。
- 该智能体还能根据需要与其他数据平台系统(元数据服务、Airflow、Spark)进行对话,以获取数据仓库之外更广泛的数据上下文。
We run a daily offline pipeline that aggregates table usage, human annotations, and Codex-derived enrichment into a single, normalized representation. This enriched context is then converted into embeddings using the OpenAI embeddings API(在新窗口中打开) and stored for retrieval. At query time, the agent pulls only the most relevant embedded context via retrieval-augmented generation(在新窗口中打开) (RAG) instead of scanning raw metadata or logs. This makes table understanding fast and scalable, even across tens of thousands of tables, while keeping runtime latency predictable and low. Runtime queries are issued to our data warehouse live as needed.
我们每日运行一个离线管道,将表的使用情况、人工标注和Codex生成的丰富信息聚合到一个单一的标准化表示中。然后,使用OpenAI的嵌入API(在新窗口中打开)将这个丰富上下文转换为嵌入表示并存储起来以供检索。在查询时,通过检索增强生成(RAG)(在新窗口中打开)的方式,智能体仅提取最相关的嵌入上下文,而不是扫描原始元数据或日志。这使得对表的理解既快速又可扩展,即使在数以万计的表格中也是如此,同时保持了运行时延迟的可预测性和低延迟。运行时查询直接在我们的数据仓库中实时发出。
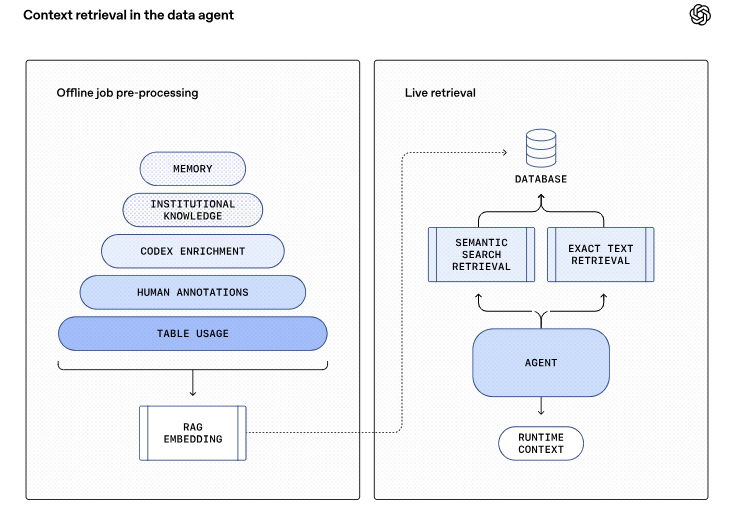
Together, these layers ensure the agent’s reasoning is grounded in OpenAI’s data, code, and institutional knowledge, dramatically reducing errors and improving answer quality.
这些层共同确保智能体的推理基于OpenAI的数据、代码和机构知识,极大地减少了错误并提高了答案质量。
Built to think and work like a teammate
构建成像队友一样思考和工作的系统
One-shot answers work when the problem is clear, but most questions aren’t. More often, arriving at the correct result requires back-and-forth refinement and some course correction.
一次性能得到回答的问题只有在问题清晰时有效,但大多数问题并不清晰。更常见的是,得出正确的结果需要根据实际需求来回调整和做一定的纠正。
The agent is built to behave like a teammate you can reason with. It’s a conversational, always-on and handles both quick answers and iterative exploration.
智能体被设计成可以与其进行推理的队友。它是一个会话式、始终在线的,可以处理快速回答和迭代探索。
It carries over complete context across turns, so users can ask follow-up questions, adjust their intent, or change direction without restating everything. If the agent starts heading down the wrong path, users can interrupt mid-analysis and redirect it, just like working with a human collaborator who listens instead of plowing ahead.
它在回合间传递完整的上下文,因此用户可以提出后续问题、调整他们的意图或改变方向,而无需重述一切。如果智能体开始走向错误的方向,用户可以在分析过程中打断它并重新引导,就像与一个倾听而不是盲目前进的人类合作伙伴一起工作一样。
When instructions are unclear or incomplete, the agent proactively asks clarifying questions. If no response is provided, it applies sensible defaults to make progress. For example, if a user asks about business growth with no date range specified, it may assume the last seven or 30 days. These priors allow it to stay responsive and non-blocking while still converging on the right outcome.
当指令不明确或不完整时,智能体会主动提出澄清问题。如果没有提供回应,它会应用合理的默认值以继续进展。例如,如果用户询问业务增长但没有指定日期范围,它可能会假设是过去七天或三十天。这些先验条件允许它在保持响应性和非阻塞的同时,仍然趋向于正确的结果。
The result is an agent that works well both when you know exactly what you want (e.g., “Tell me about this table”) and just as strong when you’re exploring (e.g., “I’m seeing a dip here, can we break this down by customer type and timeframe?”).
结果是,这个智能体在你知道自己确切想要什么时(例如,“告诉我关于这张桌子的事情”)以及你在探索时(例如,“我发现这里有一个下降趋势,我们可以按客户类型和时间范围来分析吗?”)都表现得很好。
After rollout, we observed that users frequently ran the same analyses for routine repetitive work. To expedite this, the agent’s workflows package recurring analyses into reusable instruction sets. Examples include workflows for weekly business reports and table validations. By encoding context and best practices once, workflows streamline repeat analyses and ensure consistent results across users.
在推出后,我们观察到用户经常为日常重复性工作运行相同的分析。为了加快这一过程,智能体的工作流程将重复分析打包成可重用的指令集。例如,包括每周商业报告和表格验证的工作流程。通过一次编码上下文和最佳实践,工作流程简化了重复分析,并确保用户之间结果的一致性。

Moving fast without breaking trust
快速获得答案而不破坏结果的质量水平
Building an always-on, evolving agent means quality can drift just as easily as it can improve. Without a tight feedback loop, regressions are inevitable and invisible. The only way to scale capability without breaking trust is through systematic evaluation.
构建一个始终在线、不断进化的智能体意味着质量可以像它改进一样轻易地下降。没有紧密的反馈循环,退化是不可避免的且看不见的。在不破坏信任的情况下扩大能力,唯一的方法是通过系统性的评估。
In this section, we’ll discuss how we leverage OpenAI’s Evals API(在新窗口中打开) to measure and protect the agent’s response quality.
在本节中,我们将讨论我们如何利用 OpenAI 的 Evals API(在新窗口中打开)来衡量和保护智能体响应的质量。
Its Evals are built on curated sets of question-answer pairs. Each question targets an important metric or analytical pattern we care deeply about getting right, paired with a manually authored “golden” SQL query that produces the expected result. For each eval, we send the natural language question to its query-generation endpoint, execute the generated SQL, and compare the output against the result of the expected SQL.
智能体的评估建立在精心挑选的问题-答案对集合之上。每个问题都针对一个我们非常关心的重要指标或分析模式,配以一个手动编写的“黄金”SQL查询,以产生预期的结果。对于每个评估,我们将自然语言问题发送到其查询生成端点,执行生成的SQL,并将输出与预期SQL的结果进行比较。
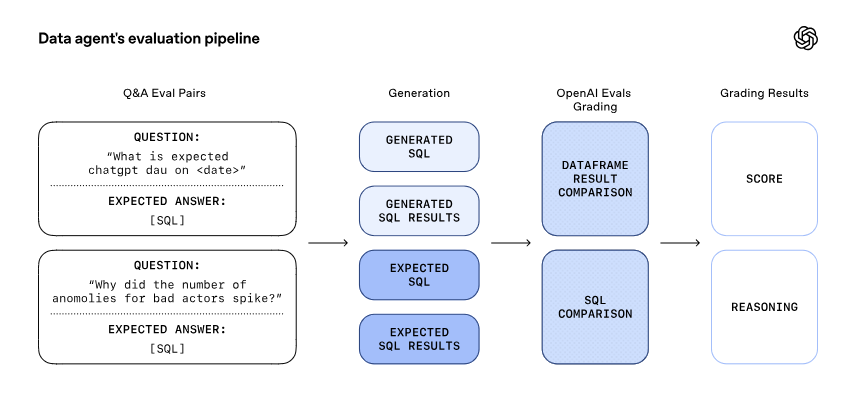
Evaluation doesn’t rely on naive string matching. Generated SQL can differ syntactically while still being correct, and result sets may include extra columns that don’t materially affect the answer. To account for this, we compare both the SQL and the resulting data, and feed these signals into OpenAI’s Evals grader. The grader produces a final score along with an explanation, capturing both correctness and acceptable variation.
评估不依赖于简单的字符串匹配。生成的SQL可能在语法上有所不同,但仍可能是正确的,结果集可能包含不影响答案的额外列。为了应对这种情况,我们比较SQL和结果数据,并将这些信号输入到OpenAI的Evals评分器。评分器会生成最终分数以及解释,同时捕捉正确性和可接受的变异。
These evals are like unit tests that run continuously during development to identify regressions as canaries in production; this allows us to catch issues early and confidently iterate as the agent’s capabilities expand.
这些评估就像在开发过程中持续运行的单元测试,可以作为生产中的哨兵来识别回归问题;这使我们能够在智能体能力扩展时及早发现问题并可信地迭代。
Agent security
智能体安全
Our agent plugs directly into OpenAI’s existing security and access-control model. It operates purely as an interface layer, inheriting and enforcing the same permissions and guardrails that govern OpenAI’s data.
我们的智能体直接连接到 OpenAI 现有的安全和访问控制模型。它纯粹作为一个接口层,继承并执行管理 OpenAI 数据的相同权限和限制。
All of the agent’s access is strictly pass-through, meaning users can only query tables they already have permission to access. When access is missing, it flags this or falls back to alternative datasets the user is authorized to use.
所有智能体的访问都是严格透传的,这意味着用户只能查询他们已有权限访问的表。当访问权限缺失时,它会标记此情况或回退到用户有权限使用的替代数据集。
Finally, it’s built for transparency. Like any system, it can make mistakes. It exposes its reasoning process by summarizing assumptions and execution steps alongside each answer. When queries are executed, it links directly to the underlying results, allowing users to inspect raw data and verify every step of the analysis.
最后,它注重透明度。像任何系统一样,它可能会出错。它会通过总结假设和执行步骤,在每条答案旁边展示其推理过程。当执行查询时,它会直接找到最终的结果,使用户能够检查原始数据并验证分析的每一步。
Lessons learned
可积累的经验
Building our agent from scratch surfaced practical lessons about how agents behave, where they struggle, and what actually makes them reliable at scale.
从头开始构建我们的智能体,让我们获得了关于智能体行为逻辑、智能体运营时会遇到的困难以及使它们在规模运用上真正可靠的实用经验。
Lesson #1: Less is More
课程 #1:少即是多
Early on, we exposed our full tool set to the agent, and quickly ran into problems with overlapping functionality. While this redundancy can be helpful for specific custom cases and is more obvious to a human when manually invoking, it’s confusing to agents. To reduce ambiguity and improve reliability, we restricted and consolidated certain tool calls.
早期,我们将我们的完整工具集暴露给智能体,很快遇到了功能冗余的问题。虽然这种冗余在某些特定定制案例中可能有所帮助,并且对于人类在手动调用时更为明显,但对于智能体来说却是很令人困惑。为了减少歧义并提高可靠性,我们限制了某些工具调用的数据范围,并进行了整合。
Lesson #2: Guide the Goal, Not the Path
第2课:引导目标,而非路径
We also discovered that highly prescriptive prompting degraded results. While many questions share a general analytical shape, the details vary enough that rigid instructions often pushed the agent down incorrect paths. By shifting to higher-level guidance and relying on GPT‑5’s reasoning to choose the appropriate execution path, the agent became more robust and produced better results.
我们也发现,高度规定的提示降低了结果质量。虽然许多问题享有通用性的分析逻辑,但细节差异足够大,使得严格的指令往往使智能体走入了错误的道路。通过转向更高层次的指导,并依靠 GPT-5 的推理来选择适当的执行路径,智能体变得更加稳健,并产生了更好的结果。
Lesson #3: Meaning Lives in Code
第3课:意义存在于代码
Schemas and query history describe a table’s shape and usage, but its true meaning lives in the code that produces it. Pipeline logic captures assumptions, freshness guarantees, and business intent that never surface in SQL or metadata. By crawling the codebase with Codex, our agent understands how datasets are actually constructed and is able to better reason about what each table actually contains. It can answer “what’s in here” and “when can I use it” far more accurately than from warehouse signals alone.
数据库结构和查询历史描述了表的结构和使用情况,但它的真正意义在于产生它的代码中。智能体管道逻辑捕捉了假设、新鲜度保证和业务意图,这些在SQL或元数据中从未表露出来。通过使用Codex来爬取代码库,我们的智能体理解了数据集是如何实际构建的,并能更好地推断出每个表实际上包含的内容。它能够比仅从仓库信号中更准确地回答“这里有什么”和“我什么时候可以使用它”。
Same vision, new tools
同一愿景,新工具
We’re constantly working to improve our agent by increasing its ability to handle ambiguous questions, improving its reliability and accuracy with stronger validations, and integrating it more deeply into workflows. We believe it should blend naturally into how people already work, instead of functioning like a separate tool.
我们不断努力提升智能体的能力,以更好地处理模糊性问题,通过更严格的验证提高其可靠性和准确性,并将其更深入地集成到工作流程中。我们相信它应该自然地融入人们现有的工作方式,而不是像独立工具那样运行。
While our tooling will keep benefiting from underlying improvements in agent reasoning, validation, and self-correction, our team’s mission remains the same: seamlessly deliver fast, trustworthy data analysis across OpenAI’s data ecosystem.
虽然我们的工具将不断从智能体推理、验证和自我校正的业务操作中获益,但我们团队的使命保持不变:在OpenAI的数据生态系统中无缝提供快速、可靠的数据分析。
Author
Bonnie Xu, Aravind Suresh, Emma Tang
Acknowledgements
Special thanks to the Data Productivity and Data Science teams, as well as to our many cross-functional users for their experimentation and feedback.
发表评论